Overview
RedPen is an open source proofreading tool to check if your technical documents meet writing standards.
RedPen Quickstart
This quickstart guide is to help you get started with RedPen. Let’s go through some of the basics.
Requirements
RedPen requires the following software.
-
Java 1.8.40 or greater
Example run
First, download the RedPen package from release page, and then decompress the package with the following commands.
$ tar xvf redpen-*-assembled.tar.gz
$ cd redpen-*Then, run the redpen command with the supplied sample document and configuration file.
$ bin/redpen -c conf/redpen-conf-en.xml sample-doc/en/sampledoc-en.txt
14:32:37.639 [main] INFO org.unigram.docvalidator.Main - loading character table file: sample/conf/symbol-conf-en.xml
14:32:37.652 [main] INFO o.u.docvalidator.util.CharacterTable - Succeeded to load character table
14:32:37.654 [main] INFO o.unigram.docvalidator.parser.Parser - comma is set to ","
14:32:37.655 [main] INFO o.unigram.docvalidator.parser.Parser - full stop is set to "."
14:32:37.663 [main] INFO o.u.d.v.s.ParagraphStartWithValidator - Using the default value of paragraph_start_with.
CheckError[sample/doc/txt/en/sampledoc-en.txt: 0] = The length of the line exceeds the maximum 265 in line: ln bibliometrics and link analysis studies many attempts have been made to analyze the \
relationship amongscientific papers, authors andjoumals and recently, these research results have been found to be effective for analyzing the link structure ofweb pages as we11.
CheckError[sample/doc/txt/en/sampledoc-en.txt: 0] = The length of the line exceeds the maximum 161 in line: In addition, Most of these methods are concernedwith the two link analysis measures: \
relatedness between documenatsndglobal importance of individual documents.
...RedPen Commands
RedPen provides both a simple standalone command line tool and a server.
Command line tool
RedPen provides a simple command line tool called 'redpen' to check documents.
Using redpen
We use the redpen command as follows.
$ redpen [options] input-filesBy default, input files are delimited by whitespace and then analysed. The redpen command supports the following options.
Options
The redpen command has the following options.
Specify the RedPen configuration file
-c <CONFIG_FILE>, --configuration <CONFIG_FILE>
RedPen CLI (redpen command) search the configuration file when users do not
specify the configuration file with -c option.
First RedPen loads redpen-conf.xml in the current directory.
If redpen-conf.xml does not exist in the current directory,
RedPen loads the localized setting file, redpen-conf-{lang}.xml in current directory,
where {lang} is language code in ISO 639-1.
The language codes are selected with the locale setting of the users computer.
When there is no localized setting file, RedPen try to load the configuration file in $REDPEN_HOME/conf.
Input file format [default: plain]
-f <INPUT_FORMAT>, --input_format <INPUT_FORMAT>
This argument specifies the input format. Currently RedPen supports the following formats.
| Value | Description |
|---|---|
plain |
Plain text format |
wiki |
Wiki (Textile) format |
markdown |
Markdown format |
asciidoc |
AsciiDoc format |
review |
Re:VIEW format |
latex |
LaTeX format |
properties |
Java property file format |
|
Note
|
When users do not specify the input format with -f, redpen command guess the format from file extensions.
The followings table shows the list of file extensions, which redpen command understand.
|
| Value | Extension |
|---|---|
plain |
txt |
wiki |
wiki |
markdown |
md, markdown |
asciidoc |
adoc, asciidoc |
review |
re, review |
latex |
tex, latex |
properties |
properties |
rest |
reStructuredText |
Result format [default: plain]
option:: -r <RESULT_FORMAT>, --result_format <RESULT_FORMAT>
This argument determines the output format. Currently RedPen supports the following output formats.
| Value | Description |
|---|---|
plain |
plain text format |
plain2 |
an alternate plain text format collated by sentence |
xml |
xml format |
json |
json format |
json2 |
an alternate json format collated by sentence |
Specify the limit of error number [default: 1]
The redpen command returns 0 when the number of found errors are less than the specified limit.
option:: -l <LIMIT NUMBER>, --limit <LIMIT NUMBER>
Specify the language of error messages [default: depends on the locale settings of the machine]
For selecting language of errors, we specify the language code (en or ja).
option:: -L <LANGUAGE>,--lang <LANGUAGE>
Specify the input sentences
Commonly users specify input files, but sometimes making files is tidious. For testing purpose redpen command provides the parameter for input sentences.
option:: -s <INPUT SENTENCE>, --sentence <INPUT SENTENCE>
Display help
-h, --help
Show the redpen version
--version
RedPen server
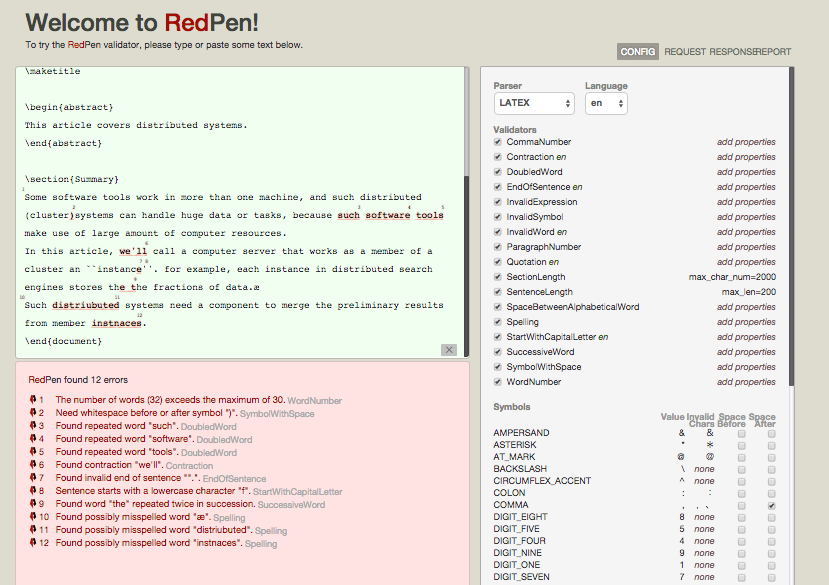
RedPen also provides the server. RedPen server provides not only UI but also practical REST API (see RedPen Server section). The following is an image of RedPen server UI.
Usage: redpen-server
We can start and stop the redpen server with the following command.
$ redpen-server [start|stop]Configuration
The redpen-server command is able to be configured with editing the variables in redpen-server file itself. The following table shows the configuration variables and the default values.
| Configuration | Default Value | Description |
|---|---|---|
REDPEN_PORT |
8080 |
Specify Port number of RedPen server. |
STOP_KEY |
redpen.stop |
RedPen server is able to stop with Stop key with http access. If you do not want to stop with stop key comment out the value. |
REDPEN_CONF_FILE |
Specify default redpen config file. |
|
REDPEN_LANGUAGE |
Depends on locale settings |
Specify the language of error messages from RedPen. |
The functionality of the RedPen server is described in the RedPen Server section.
RedPen Input Formats
RedPen supports several types of input formats:
-
Plain Text
-
Markdown
-
AsciiDoc
-
Wiki
-
LaTeX
-
Re:VIEW
-
Java Properties
-
reStructuredText
Plain text
Plain text supports a set of paragraphs. Paragraphs are separated by two new lines. For example, the following article has two paragraphs.
This is a first paragraph. This paragraph is the introduction of this article. It introduces the central issue discussed throughout the rest of the article. Second paragraph describes the details of the issue and attempts to present a solution.
AsciiDoc
See the AsciiDoctor reference
LaTeX
|
Note
|
RedPen does not supports Macros defined by writers. |
Wiki format
RedPen supports a subset of Wiki syntax. Currently, the supported elements of Wiki syntax are as follows.
Headings
To create a heading, add a line starting with h[1234]. The number after h represents the level of the heading or section.
Inline Formatting
RedPen supports the following inline formatting.
Bold
**this is a Bold sentence.**
Italic
//this is an italic sentence.//
Underline
__this is an underlined sentence.__
Strikethrough
--this is a strikethrough sentence.--
Links
Links elements are included in Wiki formatted documents.
Lists
Wiki syntax supports two types of lists.
Bulleted Lists
To enter a bulleted list, start a line with an asterisk. The number of asterisks denotes the indent level of the list.
* List * List ** Sub List
Numbered List
If you want to add numbered lists, use the hash/pound symbol (#) instead of the asterisk used by Bulleted Lists.
Comments
To add a comment to the wiki source, add a [!-- … --] block. The
following shows a sample comment.
[!-- This is a comment. --]
Paragraphs
Paragraphs are separated by two new lines. This syntax is the same as for plain text.
Markdown
RedPen currently supports the following Markdown elements.
Headings
Two styles of headings are supported.
-
Underlined headings
First and second level headings can be specified using underlines.
First-level headings ====================
second-level headings ---------------------
-
Atx style headings
1-6 hash or pound characters (#) at the beginning of a line.
For example:
# First-level heading ## Second-level heading ### Third-level heading
Inline Formatting
RedPen supports the following inline formatting.
Bold
Wrap characters with double asterisks or underscores for bold. The following are samples of bold sentences.
**this is a Bold sentence.** __this is also a Bold sentence.__
Italic
Wrap characters with a single asterisk or underscore for italics. The following are samples of italic sentences.
*this is a italic syntax.* _this is also a italic syntax._
Links
To create a link, wrap square brackets around the link’s label and parentheses around the URL. For example.
[label](url)
Lists
The Markdown parser used by RedPen supports two types of lists - Bulleted lists and Numbered lists.
Bulleted Lists
To create a bulleted list, start a line with an asterisk or a hyphen. The lists are nested according to how many leading spaces there are. The following is a example of a bulleted list using asterisks.
* List * List * Sub List * Sub List
Numbered List
If you want to create a numbered list, use a number followed by a period, as in the following example.
1. List 2. List
Paragraphs
Paragraphs are separated by two new lines. This syntax is the same as for plain text.
Re:VIEW format
See the Re:VIEW reference
Java Properties
Properties files or Resource Bundles are commonly used for internalization in Java. RedPen treats every property as a section, which can have one or more sentences. Comments and values, but not keys are validated.
See the Properties Javadoc for more information on file format.
RedPen Output Formats
RedPen supports three basic output formats - Plain text, XML, and JSON.
Plain text
Plain text output format consists of the following lines.
FILE_NAME:LINE_NUM: ValidationError[ERROR_TYPE], ERROR_MESSAGE at line: SENTENCE
An alternate plain text form (plain2) prints each sentence, followed by all of the errors found in the sentence.
XML
The top section of the XML output format is validation-result element which contains multiple error sections. Each error section has the following sub-elements.
Block |
Optional |
Description |
|
false |
Validator name |
|
false |
Error message |
|
false |
Line Number |
|
false |
Sentence containing error |
|
true |
File name |
JSON
Block |
Optional |
Description |
|
false |
Validator name |
|
false |
Error message |
|
false |
Line Number |
|
false |
Sentence containing error |
|
true |
File name |
The alternative JSON output format (json2) collates each error by the sentence it relates to.
RedPen Configuration
RedPen’s configuration file consists of two separate blocks. One block configures the RedPen validators and the other lets you override characters and symbols for the input documents.
Configuration file
RedPen has a single configuration file, which contains all the settings RedPen requires. The main configuration file is an xml file with a root element of redpen-conf. Within this element there are two sub elements named "validators" and "symbols."
To apply the default validators and symbol settings for a target language, we just specify lang attributes in the redpen-conf element.
The validators section specifies which validators are to be loaded by RedPen. Each validator within this section can have their property values overridden.
The symbols section overrides the default symbol settings for the target language. The following is an example of a RedPen configuration file.
<redpen-conf lang="en">
<validators>
<validator name="SentenceLength">
<property name="max_len" value="200"/>
</validator>
<validator name="InvalidSymbol" />
<validator name="SpaceWithSymbol" />
<validator name="SectionLength">
<property name="max_num" value="2000"/>
</validator>
<validator name="ParagraphNumber" />
</validators>
<symbols>
<symbol name="EXCLAMATION_MARK" value="!" invalid-chars="!" after-space="true" />
<symbol name="LEFT_QUOTATION_MARK" value="\'" invalid-chars="“" before-space="true" />
</symbols>
</redpen-conf>In the next section we will cover the configuration of validators in greater detail. The settings for the symbols section are described in the Setting Symbols section.
Validator configuration
The RedPen configuration file contains a "validators" section for registering Validators. RedPen will apply each validator specified in this section to the to the input document.
The following is a sample "validators" section.
<validators>
<validator name="SentenceLength">
<property name="max_len" value="200"/>
</validator>
<validator name="InvalidSymbol" />
<validator name="SpaceWithSymbol" />
<validator name="SectionLength">
<property name="max_num" value="2000"/>
</validator>
<validator name="ParagraphNumber" />
</validators>Each validator is configured within its own validator element. The name attribute of this element specifies the name of the function (called validator). Each validator is responsible for checking a particular aspect of the input document. For example, if the "SectionLength" is added in the configuration, then RedPen will check the length of each section in the input document.
Some validator components can be configured using "property" elements. For example, you can override the maximum character count in the "SectionLength" validator by specifying a "max_num" property. Some validators also have "sub-validators" which can also be configured within the validator section.
We cover all supported validators in the Validator section.
Setting symbols
The lang attribute of the redpen-conf element determines how various symbols are handled by RedPen. RedPen supports default symbols for "en" and "ja", which are described in English symbols and Japanese Symbols.
The default symbol settings for a target language can be overridden by configuring the symbols section of the RedPen configuration file.
The default settings are described in the following sections. Within the symbols configuration section we can use symbol elements to specify which symbols to use when validating documents. Each "symbol" element overrides a character found in the documents.
The following table describes the properties of the symbol element.
| Property | Mandatory | Default Value | Description |
|---|---|---|---|
|
true |
none |
Name of the symbol |
|
true |
none |
Value of the symbol |
|
false |
false |
Need space before the symbol |
|
false |
false |
Need space after the symbol |
|
false |
"" |
List of invalid symbols |
Sample: Setting symbols
In the following example, we can see a symbols section that defines 3 symbols. The first element defines exlamation mark as '!'. Then, FULL_STOP defines a period as the character "." and specifies that the symbol must be followed by a space. The third element defines comma as ',' and also defines '、' and ',' as invalid comma characters. This is because some characters have equivalent symbolic meanings.
For example, in Japanese both '.' and '。' can represent a FULL_STOP. The invalid-chars setting allows us to restrict which character alternatives are permitted in our documents.
<symbols>
<symbol name="EXCLAMATION_MARK" value="!" />
<symbol name="FULL_STOP" value="." after-space="true" />
<symbol name="COMMA" value="," invalid-chars="、," after-space="true" />
</symbols>Default Settings for English
The following table shows the default symbol settings for English and other latin based documents. In the table, the first column contains the name of each symbol and the second column (Value) shows the symbol’s character value. The columns 'NeedBeforeSpace', 'NeedAfterSpace' indicate if the symbol should be followed by or preceded by a space, respectively. The column, 'InvalidChars' shows the symbol’s invalid variant characters.
| Symbol | Value | NeedBeforeSpace | NeedAfterSpace | InvalidChars | Description |
|---|---|---|---|---|---|
|
'.' |
false |
true |
'.', '。' |
Sentence period |
|
' ' |
false |
false |
' ' |
White space between words |
|
'!' |
false |
true |
'!' |
Exclamation mark |
|
'#' |
false |
false |
'#' |
Number sign |
|
'$' |
false |
false |
'$' |
Dollar sign |
|
'%' |
false |
false |
'%' |
Percent sign |
|
'?' |
false |
true |
'?' |
Question mark |
|
'&' |
false |
true |
'&' |
Ampersand |
|
'(' |
true |
false |
'(' |
Left parenthesis |
|
')' |
false |
true |
')' |
Right parenthesis |
|
'*' |
false |
false |
'*' |
Asterrisk |
|
',' |
false |
true |
'、',',' |
Comma |
|
'+' |
false |
false |
'+' |
Plus sign |
|
'-' |
false |
false |
'ー' |
Hyphenation |
|
'/' |
false |
false |
'/' |
Slash |
|
':' |
false |
true |
':' |
Colon |
|
';' |
false |
true |
';' |
Semicolon |
|
'<' |
false |
false |
'<' |
Less than sign |
|
'>' |
false |
false |
'>' |
Greater than sign |
|
'=' |
false |
false |
'=' |
Equal sign |
|
'@' |
false |
false |
'@' |
At mark |
|
'[' |
true |
false |
Left square bracket |
|
|
']' |
false |
true |
Right square bracket |
|
|
'\' |
false |
false |
Backslash |
|
|
'^' |
false |
false |
'^' |
Circumflex accent |
|
'_' |
false |
false |
'_' |
Low line (under bar) |
|
'{' |
true |
false |
'{' |
Left curly bracket |
|
'}' |
true |
false |
'}' |
Right curly bracket |
|
'|' |
false |
false |
'|' |
Vertical bar |
|
'~' |
false |
false |
'〜' |
Tilde |
|
''' |
false |
false |
Left single quotation mark |
|
|
''' |
false |
false |
Right single quotation mark |
|
|
'"' |
false |
false |
Left double quotation mark |
|
|
'"' |
false |
false |
Right double quotation mark |
These settings are used by several Validators such as InvalidSymbol and SpaceValidator.If you change the symbol definition, you can override the settings adding symbol elements to the symbols block in the configuration file.
Default Settings for Japanese
The following table shows the default symbol settings for Japanese documents.
| Symbol | Value | NeedBeforeSpace | NeedAfterSpace | InvalidChars | Description |
|---|---|---|---|---|---|
|
'。' |
false |
false |
'.','.' |
Sentence period |
|
' ' |
false |
false |
White space between words |
|
|
'!' |
false |
false |
'!' |
Exclamation mark |
|
'#' |
false |
false |
'#' |
Number sign |
|
'$' |
false |
false |
'$' |
Dollar sign |
|
'%' |
false |
false |
'%' |
Percent sign |
|
'?' |
false |
false |
'?' |
Question mark |
|
'&' |
false |
false |
'&' |
Ampersand |
|
'(' |
false |
false |
'(' |
Left parenthesis |
|
')' |
false |
false |
')' |
Right parenthesis |
|
'*' |
false |
false |
'*' |
Asterrisk |
|
'、' |
false |
false |
',',',' |
Comma |
|
'+' |
false |
false |
'+' |
Plus sign |
|
'ー' |
false |
false |
'-' |
Hyphenation |
|
'/' |
false |
false |
'/' |
Slash |
|
':' |
false |
false |
'' |
Colon |
|
';' |
false |
false |
'' |
Semicolon |
|
'<' |
false |
false |
'' |
Less than sign |
|
'>' |
false |
false |
'' |
Greater than sign |
|
'=' |
false |
false |
'=' |
Equal sign |
|
'@' |
false |
false |
'@' |
At mark |
|
'「' |
true |
false |
Left square bracket |
|
|
'」' |
false |
false |
Right square bracket |
|
|
'¥' |
false |
false |
Backslash |
|
|
'^' |
false |
false |
'^' |
Circumflex accent |
|
'_' |
false |
false |
'_' |
Low line (under bar) |
|
'{' |
true |
false |
'{' |
Left curly bracket |
|
'}' |
true |
false |
'}' |
Right curly bracket |
|
'|' |
false |
false |
'|' |
Vertical bar |
|
'〜' |
false |
false |
'~' |
Tilde |
|
'‘' |
false |
false |
Left single quotation mark |
|
|
'’' |
false |
false |
Right single quotation mark |
|
|
'“' |
false |
false |
Left double quotation mark |
|
|
'”' |
false |
false |
Right double quotation mark |
Japanese Symbol Variations
Symbols in Japanese has vary by the author and the writing group. RedPen provides three default symbol settings for Japanese. The variations are specified with variant attribute. Currently there are three variants for Japanese symbol settings ("zenkaku" (default), "zenkaku2" and "hankaku").
For example the following is the sample of configuration file for Japanese text with the "zenkaku2" setting.
<redpen-conf lang="ja" variant="zenkaku2">
<validators>
<validator name="InvalidSymbol" />
<validator name="SpaceWithSymbol" />
<validator name="SectionLength" />
<validator name="ParagraphNumber" />
</validators>
</redpen-conf>The symbols of "hankaku" variant is the same as the symbol settings as en. The symbols of "zenkaku2" is almost the same as default "zenkaku" variant of "ja" with the following exceptions.
| Symbol | Value | NeedBeforeSpace | NeedAfterSpace | InvalidChars | Description |
|---|---|---|---|---|---|
FULL_STOP |
'.' |
false |
false |
' .', '。' |
Sentence period |
COMMA |
',' |
false |
false |
',','、' |
Comma |
RedPen Language Settings
RedPen processes documents written in any language, such as German, French or Japanese. RedPen default configuration will process documents written in English or other Latin-based languages. Therefore, to make RedPen process documents written in other languages, users need to specify the language in the configuration file.
Override Language
Currently there are two language settings, en, ja and ru. en is for documents written in Latin-based languages such as English and German. "ja" is for Japanese documents.
In order to override the language, you must change the "lang" property of the "symbols" section of the configuration file. In the following example, the config file specifies Japanese ("ja") as the document language.
<symbols lang="ja">
<symbol name="EXCLAMATION_MARK" value="!" invalid-chars="!" after-space="true" />
<symbol name="LEFT_QUOTATION_MARK" value="\'" invalid-chars="“" before-space="true" />
<symbol name="RIGHT_QUOTATION_MARK" value="\'" invalid-chars="”" after-space="true" />
<symbol name="NUMBER_SIGN" value="#" invalid-chars="#" after-space="true" />
<symbol name="FULL_STOP" value="。" invalid-chars=".." after-space="true" />
<symbol name="COMMA" value="、" invalid-chars="," after-space="true" />
</symbols>Override Symbol Settings
Depending on the documents and their authors, the characters and symbols used may differ. For example, one author prefers "'" for a left single quotation mark, whereas another author prefers to use "‘" for a left single quotation mark.
For such cases, RedPen provides the way to override the default symbols (see Setting Symbols section) used in the document. In addition, specify which symbols should not used in the input documents.
The following overrides the setting for single quotation marks to enforce the use of the ascii quotation mark (').
<symbols>
<symbol name="LEFT_SINGLE_QUOTATION_MARK" value="'" invalid-chars="‘" />
<symbol name="RIGHT_SINGLE_QUOTATION_MARK" value="'" invalid-chars="’"/>
</symbols>RedPen Supported Validators
RedPen supports the following validators.
SentenceLength
SentenceLength validator checks the length of sentences in the input document. If the length of the sentence is greater than the specified maximum length, the validator generates a warning.
Properties
| Property | Default Value | Description |
|---|---|---|
|
50 |
Maximum length of sentence. |
Supported languages
SentenceLength can be applied to any language.
InvalidExpression
InvalidExpression validator checks if input sentences contain invalid expressions (words or phrases). If the input sentence contains invalid expressions, the validator generates a warning.
Properties
| Property | Default Value | Description |
|---|---|---|
|
None |
File name of dictionary. |
|
None |
List of invalid expressions delimited by commas. |
The dictionary is a set of words or expressions. The following is an example of a dictionary.
like you know hey kidding ...
Supported languages
InvalidExpression can be applied to any language.
InvalidWord
InvalidWord validator checks if input sentences contain invalid words. If the input sentence contains invalid words, the validator generates a warning.
Properties
| Property | Default Value | Description |
|---|---|---|
|
None |
File name of dictionary. |
|
None |
List of invalid expressions delimited by commas. |
The dictionary is a set of words. The following is an example of a dictionary.
like hey wow ...
Supported Languages
InvalidWord can be any of languages (but the default dictionaries are supplied only for English and Japanese).
SpaceBeginningOfSentenceValidator
This validator checks if there is a white space at the end of sentences (except for the last sentence of paragraph). If the input sentence does end with a white space, a warning is given.
|
Warning
|
SpaceBeginningOfSentenceValidator is deprecated. |
Supported languages
SpaceBeginningOfSentenceValidator can be applied to any language.
CommaNumber
CommaNumber validator checks the number of commas in a sentence.
Properties
| Property | Default Value | Description |
|---|---|---|
|
3 |
Maximum number of commas in a sentence. |
Supported languages
CommaNumber can be applied to any language.
WordNumber
WordNumber validator checks the number of words in one setnece.
Properties
| Property | Default Value | Description |
|---|---|---|
|
30 |
Maximum number of words in a sentence. |
Supported languages
WordNumber can be applied to any languages except for several Asian languages (Chinese or Thai). RedPen does not have the tokenizer for the languages.
SuggestExpression
SuggestExpression validator works in a similar way to the InvalidExpression validator. If the input sentence contains invalid expressions, this validator returns a warning suggesting the correct expression.
Properties
| Property | Default Value | Description |
|---|---|---|
|
None |
File name of dictionary. |
The dictionary is a TSV file with two columns. First column contains the invalid expression, and the second column contains a suggested replacement expression.
SVM Support Vector Machine LLVM Low Level Virtual Machine ...
Supported languages
SuggestExpression can be any of languages but the default dictionaries are provided only for English and Japanese.
InvalidSymbol
Some symbols or characters have alternate characters with the same role. For example question mark ? (0x003F) has another unicode variation ?(0xFF1F). InvalidSymbol checks if input sentences contains invalid characters or symbols. The symbols settings are added into the character setting block int the configuration file. In this file, we write the symbols we should use in the document and their invalid counterparts. The details of these settings is described in the next section.
Supported languages
InvalidSymbol works for any langugages. See the settings of symbols in the Configuration section.
SymbolWithSpace
Some symbols need space before or after them. For example, if we want to ensure a space before a left parentheses, we can add the preference to the symbol setting block (see Setting symbols)
Supported languages
InvalidSymbol works for any language.
KatakanaEndHyphen
KatakanaEndHyphen validator checks the end hyphens of Katakana words in Japanese documents. Japanese Katakana words have variations in their end hyphen. For example, "computer" is written in Katakana as "コンピュータ" (without hyphen), and "コンピューター" (with hypen). This validator checks to ensure that Katakana words match the predefined standard. See JIS Z8301, G.6.2.2 b) G.3.
-
a: Words of 3 characters or more cannot have an end hyphen.
-
b: Words of 2 characters or less can have an end hyphen.
-
c: A compound word should apply a and b to each component word.
-
d: In the cases from a to c, the length of a syllable which is represented by a hyphen is 1 except for Youon.
Supported languages
KatakanaEndSymbol works only for Japanees texts.
KatakanaSpellCheck
KatakanaSpellCheck validator checks if Katakana words have variational written form. For example, if the Katakana word "インデックス" and the variational form "インデクス" exist within the same document, this validator will return a warning.
Properties
| Property | Default Value | Description |
|---|---|---|
|
None |
File name of dictionary. |
|
0.2 |
Threshold of the minimum similarity. KatakanaSpellCheck reports an error when there is a pair of words of which the similarity is more than the min_ratio. |
|
5 |
Threshold of the minimum word frequency. KatakanaSpellCheck checks words of which frequencies are less than min_freq. |
Supported languages
KatakanaSpellCheck works only for Japanese texts.
SectionLength
SectionLength validator checks the maximum number of words allowed in an section.
Properties
| Property | Default Value | Description |
|---|---|---|
|
1000 |
Maximum number of characters in a section. |
Supported languages
SectionLength works for any language.
ParagraphNumber
ParagraphNumber validator checks the maximum number of paragraphs allowed in one section.
Properties
| Property | Default Value | Description |
|---|---|---|
|
5 |
Maximum number of paragraphs in a section. |
Supported languages
ParagraphNumber works for any language.
ParagraphStartWith
ParagraphStartWith validator checks to see if the characters at the beginning of paragraphs conforms to the correct style.
Properties
| Property | Default Value | Description |
|---|---|---|
|
" " |
Characters in the beginning of paragraphs. |
Supported languages
ParagraphStartWith works for any langugaes.
SpaceBetweenAlphabeticalWord
SpaceBetweenAlphabeticalWord validator checks that alphabetic words are surrounded with whitespace. This validator is used in non-latin languages such as Japanese or Chinese.
Properties
| Property | Default Value | Description |
|---|---|---|
|
false |
Speces are enforce (false) or forbidden. |
|
"" |
Skip errors when there is no space before the specifed characters (symbols). |
|
"" |
Skip errors when there is no space after the specifed characters (symbols). |
Supported languages
SpaceBetweenAlphabeticalWord works for languages whose words are not split by white spaces such as Japanese or Chinese.
Contraction
Contraction throws an error when contractions are used in a document in which more than half of the verbs are written in non-contracted form.
Supported languages
Contraction works only for English texts.
Spelling
Spelling validator throws an error if there are spelling mistakes in the input documents. This validator only works for English documents.
Properties
| Property | Default Value | Description |
|---|---|---|
|
None |
File name of known word dictionary. |
|
None |
List of known words delimited by commas. |
Supported languages
Spelling works only for English texts.
DoubledWord
DoubledWord validator throws an error if a word is used more than once in a sentence. For example, if an input document contains the following sentence, the validator will report an error since good is used twice.
this good item is very good.
Properties
| Property | Default Value | Description |
|---|---|---|
|
None |
File name of skip list dictionary. |
|
None |
List of skip words delimited by commas. |
Supported languages
DoubledWord works for any langages except for Chiense or other Asian languages.
|
Note
|
The default dictionaries are supplied only for Japanese and English. |
DoubledJoshi
DoubledJoshi throws an error if a Joshi (Japanese part-of-speech) is used more than once in a Japanese sentence.
Properties
| Property | Default Value | Description |
|---|---|---|
|
None |
File name of skip list dictionary. |
|
None |
List of skip words delimited by commas. |
Supported languages
DoubledJoshi works only for Japanese
SuccessiveWord
SuccessiveWord validator throws an error if the same word is used twice in succession. For example, if an input document contains the following sentence, the validator will report an error since is is used twice in succession.
the item is is very good.
Supported languages
SuccessiveWord works for any langages except for Chiense or other Asian languages.
DuplicatedSection
DuplicatedSection validator throws an error if there are section pairs which have almost the same content.
Supported languages
DuplicatedSection works for any language.
JapaneseStyle
JapaneseStyle validator reports errors if the input file contains both "dearu" and "desu-masu" style.
Supported languages
JapaneseStyle works only for Japanese
DoubleNegative
DoubleNegative validator reports errors when input sentence contains double negative expression.
Supported languages
DoubleNegative works only for English and Japanese texts.
FrequentSentenceStart
This validator reports an error if too many sentences start with the same sequence of words.
Properties
| Property | Default Value | Description |
|---|---|---|
|
3 |
Number of words starting each sentence to consider. |
|
25 |
Maximum percentage of sentences that can start with the same words. |
|
5 |
Minimum number of sentences required for the validator to report errors. |
Supported languages
FrequentSentenceStart works for any language.
UnexpandedAcronym
This validator ensures that there are candidates for expanded versions of acronyms somewhere in the document.
That is, if there exists an acronym ABC in the document, then there must also exist a sequence of capitalized words such as Axxx Bxx Cxxx.
Properties
| Property | Default Value | Description |
|---|---|---|
|
3 |
Minimum size for the acronym |
Supported languages
UnexpandedAcronym works only for English text.
WordFrequency
This validator ensures that usage of specific words in the document don’t occur too frequently. It calculates the frequency that words are used and compares them the a reference histogram of word frequency for written English.
Excessive deviation from normal usage generates a validation error.
Properties
| Property | Default Value | Description |
|---|---|---|
|
3 |
Permitted factor of deviation from the norm. So if a word is normally used 3% of the time, your document can use it up to 9% of the time. |
|
200 |
Minimum number of words in a document before this validator starts to validate |
Supported languages
WordFrequency works only for English text.
Hyphenation
This validator ensures that sequences of words that are hyphenated in the dictionary are hyphenated in your document.
Supported languages
Hyphenation works only for English text.
NumberFormat
This validator ensures that numbers in a sentence are formatted using commas (ie: 12,000 instead of 120000), and don’t have excessive decimal points.
Properties
| Property | Default Value | Description |
|---|---|---|
|
false |
Change the decimal delimiter from . to , (as in Europe) |
|
true |
Ignore 4 digit integers (2015, 1998) |
Supported languages
NumberFormat works for texts written in European languages such as English or French.
ParenthesizedSentence
This validator generates errors if parenthesized sentences (such as this) are used too frequently, or are nested too heavily.
Properties
| Property | Default Value | Description |
|---|---|---|
|
2 |
The limit on how many parenthesized expressions are permitted |
|
1 |
The number of parenthesized expressions allowed |
|
4 |
The maximum number of words in a parenthesized expression |
Supported languages
ParenthesizedSentence works for any langugages.
WeakExpression
This validator generates errors if sequences of words form what is generally considered to be a "weak expression."
Supported languages
WeakExpression works only for English.
EndOfSentenceSentence
This validator generates errors if the style end of sentence is American style.
Supported languages
EndOfSentence works for English.
HankakuKana
This validator generates errors if the Hankaku Kana characters are used in input document.
Supported languages
HanakakuKana works only for Japanese.
Okurigana
This validator generates errors if input sentence uses invalid Okurigana Style (Japanese).
Supported languages
Okurigana works for Japanese.
StartWithCapitalLetterValidator
This validator generates errors if input sentence start with a capital character.
Supported languages
This validator works for English or other european langugages.
VoidSection
This validator generates errors if sections in input documents do not have any paragraphs or sentences.
|
Warning
|
VoidSection is deprecated and removed in the future release. Please use EmptySection. |
Properties
| Property | Default Value | Description |
|---|---|---|
|
5 |
Skip validation to the sections smaller than specified level. |
Supported languages
VoidSection works for any languages.
EmptySection
This validator generates errors if sections in input documents do not have any paragraphs or sentences.
Properties
| Property | Default Value | Description |
|---|---|---|
|
5 |
Skip validation to the sections smaller than specified level. |
Supported languages
EmptySection works for any languages.
GappedSection
This validator generates errors when the level of child sections (chapters) has the gap. For example, The following is a misplaced section sample.
= chapter 1 ... === section 1.1.1 === section 1.1.2 ...
In the above example, chapter 1 should have section 1.1 before subsection 1.1.1.
Supported languages
GappedSection works for any languages.
LongKanjiChain
This validator generates errors when input sentences has a words consist of too many Kanji characters.
In the above example, chapter 1 should have section 1.1 before subsection 1.1.1.
Properties
| Property | Default Value | Description |
|---|---|---|
|
5 |
The limit on how many characters are used in succession. |
Supported languages
GappedSection works for Japanese text.
SectionLevel
This validator generates errors when input documents contains smaller sections than specified.
Properties
| Property | Default Value | Description |
|---|---|---|
|
5 |
The limit of the sub-section level. |
Supported languages
SectionLevel works for any languages.
JapaneseAmbiguousNounConjunction
This validator generates errors when Japanese documents contains the ambiguous noun conjunction pattern. The ambigous pattern is that two nouns are conjuncted with Joshi, no (の).
The following is a sample of this pattern.
弊社の経営方針の説明を受けた。
Supported languages
JapaneseAmbigousNounConjunction works for Japanese.
JapaneseNumberExpression
JapaneseNumberExpression checks if the number expressions in the input text are in the consistent style.
Properties
| Property | Default Value | Description |
|---|---|---|
|
numeric |
Style of number expression. There is four types of styles ("numeric", "numeric-zenkaku", "kansuji", "hiragana"). |
Each style expects the following number expression.
| Style | Sample |
|---|---|
|
1つ、2つ |
|
1つ、2つ |
|
一つ、二つ |
|
ひとつ、ふたつ |
Supported languages
JapaneseNumberExpression works only for Japanese text.
JapaneseJoyoKanji
This validator generates errors when Japanese documents contains a non-joyo kanji.
The following is a sample of this pattern.
踵を返して出て行った。
Supported languages
JapaneseJoyoKanji works for Japanese.
SuccessiveSentence
SuccessiveSentence throws an error when it find almost the same sentences are in succession. This validator is useful to check the human error as follows.
The component is useful for testing. Especially for unit level testing. Especially for unit level testing. Of course we can apply it for higher level testing.
In the above sample, the same sentences are used in succession. This is a human error.
Properties
| Property | Default Value | Description |
|---|---|---|
|
3 |
Threshold of minimum distance in Edit Distance |
|
5 |
Minimum sentence length to compute |
Supported languages
SuccessiveSentence works for any languages.
ListLevel
ListLevel checks the level of list items. This validator generates errors when input sections contain list items nested too deeply.
Properties
| Property | Default Value | Description |
|---|---|---|
|
5 |
The maximum level of list items |
The following example generates an error at the six list item if max_level is five.
* one ** two *** three **** four ***** five ****** six
Supported languages
ListLevel works for any languages.
Error Suppression
Sometimes writers do not want to fix errors from RedPen. The reason is the cost to remove error is high or writer intend to break the writing standard at particular points. For such cases, RedPen support error suppression by annotation. The annotations are added just before the section containing the errors. Currently error suppression is supported for four types of formats (AsciiDoc, Markdown, Re:VIEW, LaTeX).
AsciiDoc
For AsciiDoc text, writers add the suppress annotation in attribute block. The annotation is [suppress]. For example, the following AsciiDoc text suppresses the all the erorrs in the section.
[suppress]
= Instances
Some software tools work in more than one machine, and such distributed (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources, such as CPU, Disk, and Memory.When the writers want to suppress only the specified errors, they add Validator names after suppress. For example, the following example suppresses only two types of errors (Contraction WeakExpression).
[suppress='Contraction WeakExpression']
= Instances
Some software tools work in more than one machine, and such distributed (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources, such as CPU, Disk and Memory.|
Note
|
Multi line section is not supported for suppression error with annotation. |
Markdown
For Markdown text, writers add the suppress annotation in HTML comments. Specifically Writers add annotation, @suppress in HTML comments. For example, the following text suppress all the error in the section.
<!-- @suppress -->
# Instances
Some software tools work in more than one machine, and such _distributed_ (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources, such as CPU, Disk and Memory.To suppress only specific errors, writers add the Validator names following @suppress annotation. The following sample suppresses the two type errors (Contraction WeakExpression).
<!-- @suppress Contraction WeakExpression -->
# Instances
Some software tools work in more than one machine, and such _distributed_ (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources, such as CPU, Disk and Memory.|
Note
|
Multi line comments style is not supported. |
Re:VIEW
For Re:VIEW text, writers add the suppress annotation in comments. Specifically Writers add annotation, @suppress in Re:VIEW comment #@#. For example, the following text suppress all the error in the section.
#@# @suppress
= Instances
Some software tools work in more than one machine, and such distributed (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources, such as CPU, Disk and Memory.To suppress only specific errors, writers add the Validator names following @suppress annotation. The following sample suppresses the two type errors (Contraction WeakExpression).
#@# @suppress Contraction WeakExpression
= Instances
Some software tools work in more than one machine, and such distributed (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources, such as CPU, Disk and Memory.LaTeX
For LaTeX texts, writers can add Markdown style annotation in LaTeX comment (%).
reStructuredText
For reStructuredText texts, writers can add suppress annotation in inline comments as follows.
.. @suppress Contraction WeakExpression
Distributed system
##################
Some software tools work in more than one machine, and such distributed (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources.Extending RedPen
We can make RedPen extensions with Java and JavaScript. In the following sections, we learn the way to make the extensions.
Extending RedPen with Java
RedPen users can extend RedPen by creating new Validators. This section describes how we construct Validators and covers the basics of the internal document model used by Validators.
RedPen users can create new validators for themselves or their organization. Adding validator is simple - just write a class which extends the abstract class Validator.
Extending Validators
There are several methods which users can implment for their methods (validate, prevalidate and init).
validate methods
Minimally, we just need to implement the "validate" template method.
Users need to implement the one of validate methods provided by the Validator class. Currently there are three validate methods with three different parameters.
/**
* validate the input document and returns the invalid points.
* {@link cc.redpen.validator.Validator} provides empty implementation. Validator implementation validates documents can override this method.
*
* @param document input
*/
public void validate(Document document)
/**
* validate the input document and returns the invalid points.
* {@link cc.redpen.validator.Validator} provides empty implementation. Validator implementation validates sentences can override this method.
*
* @param sentence input
*/
public void validate(Sentence sentence)
/**
* validate the input document and returns the invalid points.
* {@link cc.redpen.validator.Validator} provides empty implementation. Validator implementation validates sections can override this method.
*
* @param section input
*/
public void validate(Section section)|
Note
|
The implemented class needs to be in one of the packages: 'cc.redpen.validator', 'cc.redpen.validator.sentence' or 'cc.redpen.validator.section.' |
prevalidate method
The preValidate method called before validate method is run. This method is useful to create the prerequisite to run validate method. There are two prevalidte methods variations which have different parameters.
/**
* Process input blocks before run validation. This method is used to store
* the information needed to run Validator before the validation process.
*
* @param sentence input sentence
*/
public void preValidate(Sentence sentence)
/**
* Process input blocks before run validation. This method is used to store
* the information needed to run Validator before the validation process.
*
* @param section input section
*/
public void preValidate(Section section)Configuration properties
If validator needs Configuration properties, validator constructor can be used to define them. This way RedPen will understand that your validator supports these properties and various plugins can show them in a GUI.
/**
* @param keyValues String key and Object value pairs for supported config properties.
*/
public Validator(Object...keyValues)For example, SentencelengthValidator has a configuration property max_len, which to specifies the maximum length of sentences in input documents. Following configuration specifies the maximum length to 200.
<redpen-conf>
<validators>
...
<validator name="SentenceLength">
<property name="max_len" value="200"/>
</validator>
...
</validators>
</redpen-conf>SentenceLengthValidator loads the value of max_len automatically if it is defined in validator’s constructor. If max_len is missing from the config, the value is left as default.
public SentenceLengthValidator() {
super("max_len", 30); // Default maximum length of sentences.
}Later configuration value can be accessed via getInt("max_len") or similar methods.
In case you need to process config properties before they can be used in validate() method, you can override the init() method.
Adding Validators
There are two ways to add your Validator to RedPen.
One of the way is to add the Validator source file to the RedPen source tree and then build RedPen normally. This method is simple, but involves bundling the source code for the Validators with the source code for RedPen.
The second way is to create a Validator plugin. Creating a plugin has the advantage that you can then independently manage the source code for your Validator.
Note that in both cases, your Validator’s class name must have the suffix Validator.
In the next section, we will first explain the way to add a new Validator to Redpen’s source tree. Then we weil go thourgh the way to construct a Validator plugin.
Add a Validator to RedPen source
Let’s define a plain Validator (SentenceLengthValidator) which check if the input sentence is over 100 characters long. Then we will apply it to RedPen’s source tree.
SentenceLengthValidator
We create a PlainSentenceLengthValidator class and specify the package cc.redpen.validator.sentence. Therefore the class is stored in the redpen/redpen-core/src/main/java/cc/redpen/validator/sentence/ directory.
The following is an implementation of this class.
package cc.redpen.validator.sentence;
/**
* Validate input sentences contain more characters more than specified.
*/
public class PlainSentenceLengthValidator extends Validator {
/**
* Default constructor initializes properties with their default values.
*/
public PlainSentenceLengthValidator() {
super("max_len", 30); // Default maximum length of sentences.
}
@Override
public void validate(Sentence sentence) {
if (sentence.getContent().length() > getInt("max_len")) {
addValidationError(sentence, sentence.getContent().length(), maxLength);
}
}
}The class has a validate method which takes a Sentence object as its parameter. When this class is registered in the configuration file, RedPen automatically applies the method to each sentence in the input document.
Register a new Validator to configuration file
To register your Validator in the RedPen configuration, add the Validator’s name removing the Validator suffix, to a configuration file.
For example, to activate our newly created Validator PlainSentenceLengthValidator, include the validator element as follows:
<redpen-conf>
<validator>
...
<validator name="PlainSentenceLength" />
...
</validator>
</redpen-conf>We would then run RedPen normally, using this configuration file.
Create a Validator plugin
When creating a Validator plugin, it is often easier to start by using another plugin’s project as a template.
As an example, I have written a simple Validator plugin hankaku_kana_validator.
The most significant file for the plugin is pom.xml which exists at the
top of the project. This file is the Maven configuration file, which is
a popular software project management tool for Java.
The following is the content of pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>redpen.cc</groupId>
<artifactId>hankaku-kana-validator</artifactId>
<version>1.0-SNAPSHOT</version>
<name>hankaku-kana-validator</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>redpen.cc</groupId>
<artifactId>redpen-core</artifactId>
<version>1.2</version>
<scope>system</scope>
<systemPath>${project.basedir}/lib/redpen-core-0.6.jar</systemPath>
</dependency>
</dependencies>
</project>Usually you do not need to change the pom.xml file, except for the
contents of the artifact-id and name elements. You should alter the
name to fit the function of your Validator.
After changing pom.xml, you should delete the existing validator
file (HankakuKanaValidator.java) from "main/java/cc/redpen/validator/sentence."
Then, put your Validator’s source file in "main/java/cc/redpen/validator/sentence" or
"main/java/cc/redpen/validator/section."
Once you have included your Validator implementation, you can build the plugin.
$ mvn installIncluding a user-defined Validator plugin
When you have successfully built your Validator plugin, you can use the validator plugin in RedPen. To deply the plugin, copy the plugin’s jar file from the target directory to a directory in the classpath, such as the library directory ($REDPEN_HOME/lib). Once copied, you can add your Validator to the configuration file as described above. Remember to remove the Validator suffix from the name you enter in redpen-config.xml.
Extending RedPen in JavaScript
For those who are unfamiliar with Java, RedPen version 1.3 introduced JavaScriptValidator, which is a special validator that loads Validator implementations written in JavaScript.
Enabling JavaScriptValidator
To enable JavaScriptValidator, simply add <validator name="JavaScript"/> in your redpen-conf.xml as follows:
<redpen-conf lang="en">
<validators>
...snip...
<validator name="JavaScript" />
</validators>
</redpen-conf>Write your own validator in JavaScript
JavaScriptValidator will load all files with .js suffix from $REDPEN_HOME/js directory. This location can be overriden with script-path property of JavaScriptValidator. You can set multiple 'script-path' property.
<redpen-conf lang="en">
<validators>
...snip...
<validator name="JavaScript" >
<property name="script-path" value="/path/to/your/validator/directory-a" />
</validator>
<validator name="JavaScript" >
<property name="script-path" value="/path/to/your/validator/directory-b" />
</validator>
</validators>
</redpen-conf>Functions with the following signature will be called upon validation time:
function preValidateSentence(sentence) {
}
function preValidateSection(section) {
}
function validateDocument(document) {
// your validation logic for document here
}
function validateSentence(sentence) {
// if(your validation logic for sentence here) {
// addError('validation error message', sentence);
// }
}
function validateSection(section) {
// your validation logic for section here
}Example
Here is a JavaScript version of NumberOfCharacterValidator:
var MIN_LENGTH = 100;
var MAX_LENGTH = 1000;
function validateSentence(sentence) {
if (sentence.getContent().length() < MIN_LENGTH) {
addError("Sentence is shorter than "
+ MIN_LENGTH + " characters long.", sentence);
}
if (sentence.getContent().length() > MAX_LENGTH) {
addError("Sentence is longer than " + MAX_LENGTH
+ " characters long.", sentence);
}
}The code looks pretty much similar to the Java version.
The main difference is that the callback method validate(Sentence sentence) is referred as validateSentence(sentence) in the JavaScript version.
Run
Of course, it is JavaScript and there is no need to compile your validator.
Actually your JavaScript code will be compiled into Java byte-code by Nashorn, and it runs fast than you expect.
JavaScriptValidator will pick any *.js file located in $REDPEN_HOME/js directory.
You can simply run the redpen command to get your file validated by the js validator.
$ ./bin/redpen -c myredpen-conf.xml 2be-validated.txt
2be-validated.txt:1: ValidationError[JavaScript], [NumberOfCharacter.js] Sentence is shorter than 100 characters long. at line: very short sentence.Properties of JavaScript based extensions
We can spcify properties to JavaScript based validators. Adding properties, we can change the behaviors of the validators. Users specify the prooperties to the configuration block for the JavaScript validator. The following exmaple specify the value of propery, max_char_num to 5.
<validator name="JavaScript"> <property name="max_char_num" value="5" /> </validator>
Specified properties in JavaScript configuration block are avaiable in JavaScript extensions. For example, the following extension get the value of the property, max_char_num with getInt method.
function validateSentence(sentence) {
var content = sentence.getContent().split(" ");
var limit= getInt("max_char_num");
for(var i = 0; i<content.length;i++){
if(content[i].length >= limit){
addError("word [" + content[i] +"] is too long. length: " + content[i].length, sentence);
}
}
}
RedPen provides methods for getting values of the properties for various types The following table shows the list of provided get methods.
| Method name | Type |
|---|---|
|
Int |
|
Float |
|
String |
|
Boolean |
|
Set |
Model Structure
This section describes the internal document model structure generated by parser objects.
Generated RedPen documents consist of several blocks, which represent the elements of a document.
-
DocumentCollection represents a set of one or more files that contain a Document.
-
Document represents a single file which contains one or more Sections.
-
Section contains several blocks (Header, Paragraph, ListBlock). Except for Header, each Section can contain multiple blocks. A Section may also specify the section level and its subsections.
-
Header represents header sentences that contain a list of Sentence objects.
-
Paragraph contains one or more sentences.
-
ListBlock contains a set of ListElement objects.
The following image shows the document model used by RedPen.

RedPen Server
The RedPen server delivers the majority of RedPen’s functionality via a simple HTTP REST API.
Starting and stopping the RedPen server
Please refer to the Commands section for details on how-to start the RedPen server.
Heroku Button
RedPen server is also launch in the Heroku environment with few clicks. In the bottom of RedPen README, there is a Heroku Button.

Clicking the buttom, a RedPen server get started in Heroku. Actually the RedPen sample server in the RedPen home page is working in Heroku environment.
RedPen Server API
Configuration
/rest/config/redpens
Return the configuration for available, preconfigured redpens.
GET Parameters
-
lang=xx restricts the returned configurations to those that match the specified language. By default, all configurations are returned.
The JSON response is as follows:
{
"version": "1.1.2",
"documentParsers": ["PLAIN", "MARKDOWN", "WIKI"],
"redpens": {
"en": {
"lang": "en",
"tokenizer": "cc.redpen.tokenizer.WhiteSpaceTokenizer",
"validators": {
"CommaNumber": { "languages": [], "properties": {} },
"Contraction": { "languages": ["en"], "properties": {} },
"DoubledWord": { "languages": [], "properties": {} },
"EndOfSentence": { "languages": ["en"], "properties": {} },
"InvalidExpression": { "languages": [], "properties": {} },
"InvalidSymbol": { "languages": [], "properties": {} },
"InvalidWord": { "languages": ["en"], "properties": {} },
"ParagraphNumber": { "languages": [], "properties": {} },
"Quotation": { "languages": ["en"], "properties": {} },
"SectionLength": { "languages": [], "properties": {"max_char_num": "2000"} },
"SentenceLength": { "languages": [], "properties": {"max_len": "200"} },
"SpaceBetweenAlphabeticalWord": { "languages": [], "properties": {} },
"Spelling": { "languages": [], "properties": {} },
"StartWithCapitalLetter": { "languages": ["en"], "properties": {} },
"SuccessiveWord": { "languages": [], "properties": {} },
"SymbolWithSpace": { "languages": [], "properties": {} },
"WordNumber": { "languages": [], "properties": {} }
}
},
"ja": {
"lang": "ja",
"tokenizer": "cc.redpen.tokenizer.JapaneseTokenizer",
"validators": {
"CommaNumber": { "languages": [], "properties": {} },
"DoubledWord": { "languages": [], "properties": {} },
"HankakuKana": { "languages": ["ja"], "properties": {} },
"InvalidSymbol": { "languages": [], "properties": {} },
"KatakanaEndHyphen": { "languages": ["ja"], "properties": {} },
"KatakanaSpellCheck": { "languages": ["ja"], "properties": {} },
"ParagraphNumber": { "languages": [], "properties": {} },
"SectionLength": { "languages": [], "properties": {"max_num": "1500"} },
"SentenceLength": { "languages": [], "properties": {"max_len": "100"} },
"SpaceBetweenAlphabeticalWord": { "languages": [], "properties": {} },
"SuccessiveWord": { "languages": [], "properties": {} }
}
}
}
}-
The version property indicates the version of RedPen.
-
The documentParsers array contains all supported document parsers
-
The redpens object shows the available pre-configured redpens and how they are configured. Within each object:
-
lang specifies the language the redpen is designed for
-
tokenizer specifies the tokenizer class used by the redpen
-
validators shows which validators are configured within the redpen. This object is in a format suitable for the document/validate/json request below. For each validator:
-
The languages array indicates which languages for which the validator is suitable. An empty array indicates all languages.
-
The properties object specifies the currently configured properties for this validator, as described in validator
-
-
Document Validation
/rest/document/validate
This POST request validates a document and returns the errors.
POST Parameters
-
document contains the text of the document RedPen is to validate
-
documentParser specifies which parser should be used to parse the
- document. Valid options are
-
-
PLAIN
-
MARKDOWN
-
WIKI
-
-
lang specifies the language used to tokenize the document. Currently, values of ja (Japanese) and en (English/Whitespace) are supported.
-
The optional format field determines the format for the results. It can be one of json (the default), json2, plain, plain2 or xml.
-
The optional config field contains the contents of a RedPen XML configuration file
Examples using curl and document/validate
$ curl --data document="Twas brillig and the slithy toves did gyre and gimble in the wabe" \
--data lang=en --data format=PLAIN2 \
--data config="`cat ./redpen-server/target/classes/conf/redpen-conf.xml`" \
localhost:8080/rest/document/validate/
Line: 1, Offset: 0
Sentence: Twas brillig and the slithy toves did gyre and gimble in the wabe
Spelling: Found possibly misspelled word "brillig".
Spelling: Found possibly misspelled word "slithy".
Spelling: Found possibly misspelled word "toves".
Spelling: Found possibly misspelled word "gyre".
Spelling: Found possibly misspelled word "gimble".
Spelling: Found possibly misspelled word "wabe".
DoubledWord: Found repeated word "and".$ curl -s --data document="古池や,蛙飛び込む水の音" \
--data config="`cat ./redpen-server/target/classes/conf/redpen-conf-ja.xml`" \
localhost:8080/rest/document/validate/ | json_reformat
{
"errors": [
{
"sentence": "古池や,蛙飛び込む水の音",
"endPosition": {
"offset": 4,
"lineNum": 1
},
"validator": "InvalidSymbol",
"lineNum": 1,
"sentenceStartColumnNum": 0,
"message": "Found invalid symbol \",\".",
"startPosition": {
"offset": 3,
"lineNum": 1
}
}
]
}/rest/document/validate/json
This POST request processes a redpen validation request, specified in JSON, and returns redpen errors in a supported RedPen format.
Request format
{
"document": "Theyre is a blak rownd borl.",
"format": "json2",
"documentParser": "PLAIN",
"config": {
"lang": "en",
"validators": {
"CommaNumber": {},
"Contraction": {},
"DoubledWord": {},
"EndOfSentence": {},
"InvalidExpression": {},
"InvalidSymbol": {},
"InvalidWord": {},
"ParagraphNumber": {},
"Quotation": {},
"SectionLength": {
"properties": {
"max_char_num": "2000"
}
},
"SentenceLength": {
"properties": {
"max_len": "200"
}
},
"SpaceBetweenAlphabeticalWord": {},
"Spelling": {},
"StartWithCapitalLetter": {},
"SuccessiveWord": {},
"SymbolWithSpace": {},
"WordNumber": {}
},
"symbols": {
"AMPERSAND": {
"after_space": false,
"before_space": true,
"invalid_chars": "&",
"value": "&"
},
"ASTERISK": {
"after_space": true,
"before_space": true,
"invalid_chars": "*",
"value": "*"
}
}
}
}-
The document property specifies the text of the document to validate
-
The documentParser property should contain the name of a valid RedPen documentparser (ie: PLAIN, MARKDOWN or WIKI)
-
The format property determines the format for the results. It can be one of json, json2, plain, plain2 or xml.
-
The config object specifies the validator configuration for the request. This consists of:
-
A config object, consisting of a series of objects that are named after a RedPen validator. If the object is present, the validator will be configured. Within this named object, a properties object can be used to set the name and values of any property used by the validator.
-
The lang property indicates the language of the document. It determines how the document will be tokenized by RedPen.
-
A symbols object containing overridden symbols, as described in configuration. Each entry must be a validate symbol name, and can contain the following elements:
-
value specifies the Symbol’s value
-
invalid_chars is a string of invalid alternatives for this Symbol
-
before_space and after_space specify if a space is required before or after the Symbol.
-
-
Response (json2 format):
{
"errors": [
{
"sentence": "Theyre is a blak rownd borl.",
"position": {
"start": {
"offset": 0,
"line": 1
},
"end": {
"offset": 27,
"line": 1
}
},
"errors": [
{
"subsentence": {
"offset": 0,
"length": 6
},
"validator": "Spelling",
"position": {
"start": {
"offset": 0,
"line": 1
},
"end": {
"offset": 6,
"line": 1
}
},
"message": "Found possibly misspelled word \"Theyre\"."
},
{
"subsentence": {
"offset": 12,
"length": 4
},
"validator": "Spelling",
"position": {
"start": {
"offset": 12,
"line": 1
},
"end": {
"offset": 16,
"line": 1
}
},
"message": "Found possibly misspelled word \"blak\"."
},
{
"subsentence": {
"offset": 17,
"length": 5
},
"validator": "Spelling",
"position": {
"start": {
"offset": 17,
"line": 1
},
"end": {
"offset": 22,
"line": 1
}
},
"message": "Found possibly misspelled word \"rownd\"."
},
{
"subsentence": {
"offset": 23,
"length": 4
},
"validator": "Spelling",
"position": {
"start": {
"offset": 23,
"line": 1
},
"end": {
"offset": 27,
"line": 1
}
},
"message": "Found possibly misspelled word \"borl\"."
}
]
}
]
}Some examples using curl and document/validate/json
$ curl -s --data "document=fish and chips" http://localhost:8080/rest/document/validate | json_reformat
{
"errors": [
{
"sentence": "fish and chips",
"validator": "StartWithCapitalLetter",
"lineNum": 1,
"sentenceStartColumnNum": 0,
"message": "Sentence starts with a lowercase character \"f\"."
}
]
}$ curl -s --data "document=ここはどこでうか?&lang=ja&" http://localhost:8080/rest/document/validate | json_reformat
{
"errors": [
{
"sentence": "ここはどこでうか?",
"endPosition": {
"offset": 9,
"lineNum": 1
},
"validator": "InvalidSymbol",
"lineNum": 1,
"sentenceStartColumnNum": 0,
"message": "Found invalid symbol \"?\".",
"startPosition": {
"offset": 8,
"lineNum": 1
}
}
]
}$ curl -s --data "document=# Markdown Test%0A%0ASpellink Errah&lang=en&documentParser=MARKDOWN" http://localhost:8080/rest/document/validate | json_reformat
{
"errors": [
{
"sentence": "Spellink Errah",
"endPosition": {
"offset": 8,
"lineNum": 3
},
"validator": "Spelling",
"lineNum": 3,
"sentenceStartColumnNum": 0,
"message": "Found possibly misspelled word \"Spellink\".",
"startPosition": {
"offset": 0,
"lineNum": 3
}
},
{
"sentence": "Spellink Errah",
"endPosition": {
"offset": 14,
"lineNum": 3
},
"validator": "Spelling",
"lineNum": 3,
"sentenceStartColumnNum": 0,
"message": "Found possibly misspelled word \"Errah\".",
"startPosition": {
"offset": 9,
"lineNum": 3
}
}
]
}curl -s -H "Content-Type: application/json" \
--data '{document:"fisch and chipps",format:"plain",config:{validators:{Spelling:{},SentenceLength:{properties:{max_len:6}}}}}' \
http://localhost:8080/rest/document/validate/json
1: ValidationError[Spelling], Found possibly misspelled word "fisch". at line: fisch and chipps
1: ValidationError[Spelling], Found possibly misspelled word "chipps". at line: fisch and chipps
1: ValidationError[SentenceLength], The length of the sentence (16) exceeds the maximum of 6. at line: fisch and chippsFor Developers
Feature requests are warm welcome through the GitHub. If you are interested in joining the development team. The following instructions help you to understand building RedPen development environment. Contributions in the form of pull requests are easy to integrate to the master branch.
Development Policy
We will develop this tiny tool slowly but steadily. Therefore we would not be able to accept the proposal containing drastic changes, even when the proposed change is useful for the project.
Build RedPen
Building all the RedPen package is simple. You just run the following command.
$./mvnw clean install
The built RedPen package is flushed in redpen/redpen-distribution/target.
After you get the built RedPen package, you unzip it with the following command.
$ cd redpen/redpen-distribution/target $ tar xvf redpen-distribution-*.*.*-SNAPSHOT-assembled.tar.gz x redpen-distribution-*.*.*-SNAPSHOT/bin/ x redpen-distribution-*.*.*-SNAPSHOT/conf/ x redpen-distribution-*.*.*-SNAPSHOT/js/ x redpen-distribution-*.*.*-SNAPSHOT/js/test/ x redpen-distribution-*.*.*-SNAPSHOT/lib/ ...
Now the RedPen package is ready to use.
$cd redpen-distribution-*.*.*-SNAPSHOT
$bin/redpen -h
usage: redpen-cli [Options] [<INPUT FILE>]
-c,--conf <CONF FILE> Configuration file (REQUIRED)
-f,--format <FORMAT> Input file format
(markdown,plain,wiki,asciidoc,latex)
-h,--help Displays this help information and exits
-l,--limit <LIMIT NUMBER> error limit number
-r,--result-format <RESULT FORMAT> Output result format
(json,json2,plain,plain2,xml)
-v,--version Displays version information and exits
Testing
When you modify RedPen source files, please make sure to add the test cases to make the reviewer understand the expected behaviors. In addition run whole test cases before making the Pull Request. RedPen test cases are run with the following command.
./mvnw test
Misc Information
-
Twitter account
-
Source repository (git)
-
Chat (Gitter)
-
Issue tracker
Text Editor / IDE
Some software engineers develop RedPen packages for various editors such as Emacs or Atom. This section introduces the RedPen packages. With the following packages, we can enjoy the linting texts in the editors or IDEs.
Atom
Atom is a modern text editor which works in various platforms such as OS X, Linux, and Windows. linter-redpen is an sophisticated Atom package created by griffin-stewie. This provides real-time checking of texts.
Emacs
Emacs is a real-time display text editor. Many software engineers love this editor for the customisablity. redpen-paragraph is a Emacs package for RedPen created by karronoli.
Vim
IntelliJ IDEA
IntelliJ IDEA is a popular Java IDE (Integrated Development Environment) provided Jetbrains. But this IDE also provides many plugins to support editing markup texts such as AsiiDoc or Markdown. We have been developing IntelliJ IDEA plugin.
RedPen FAQ
This section shows the frequent asked questions and the answers.
-
Does RedPen check LaTeX documents for common style errors?
RedPen supports LaTex format from version 1.4. The following is a sample usage of the redpen command.
$ redpen -c redpen-conf.xml -f latex content.tex
Links
This section introduces the useful links related with RedPen project.